Progress & Future Plan
-
We have completed the analysis of 110 oral cancer exomes. A summary of results of this analysis is provided below.
-
Exome sequencing (n=50) and recurrence testing (n=60) reveals that some significantly and frequently altered genes are specific to OSCC-GB (USP9X, MLL4, ARID2, UNC13C and TRPM3), while some others are shared with HNSCC (for example, TP53, FAT1, CASP8, HRAS and NOTCH1). We also find new genes with recurrent amplifications (for example, DROSHA, YAP1) or homozygous deletions (for example, DDX3X) in OSCC-GB. We find a high proportion of C>G transversions among tobacco users with high numbers of mutations. Many pathways that are enriched for genomic alterations are specific to OSCC-GB. Our work reveals molecular subtypes with distinctive mutational profiles such as patients predominantly harbouring mutations in CASP8 with or without mutations in FAT1. Mean duration of disease-free survival is significantly elevated in some molecular subgroups. These findings open new avenues for biological characterization and exploration of therapies.
-
We have submitted the alligned sequence data in European Genome-phenome Archive (EGA) and the somatic alteration data in ICGC database for the benefit of research community.
-
RNA-Seq analysis has been performed on tumour tissues representative of the three different molecular subgroups of OSCC-GB identified by us. Data analysis is in progress to identify trasncriptomic alterations in these subgroups.
-
Epigenomic analysis by Illumina 450-K methylation array is planned for these groups of patients and will be undetaken soon.
-
In order to expand our identification of somatic alterations, including structural variations, in OSCC-GB, we have initiated deep whole genome sequencing of paired tumour-normal DNA samples from patients in Illumina HiSeq-2500 and 2000 platforms.
-
We intend to perform RNA-Seq and deep epigenomic analysis of these samples to generate comprehensive information on OSCC-GB.
-
ICGC and The Cancer Genome Atlas (TCGA) have launched a joint initiative to analyse whole genome sequence data of a large number of tumour and normal samples to identify genomic commonalities across major cancer types prevalent across the globe (the PAN-CANCER project). This is expected to result in identification of various pathways which are commonly altered in these cancer types. The India – Project has made a commitment to contribute deep whole genome sequence data of twenty five tumour – normal pairs from OSCC-GB patients. Data generation and upload to the ICGC PAN-CANCER data repository is in progress.
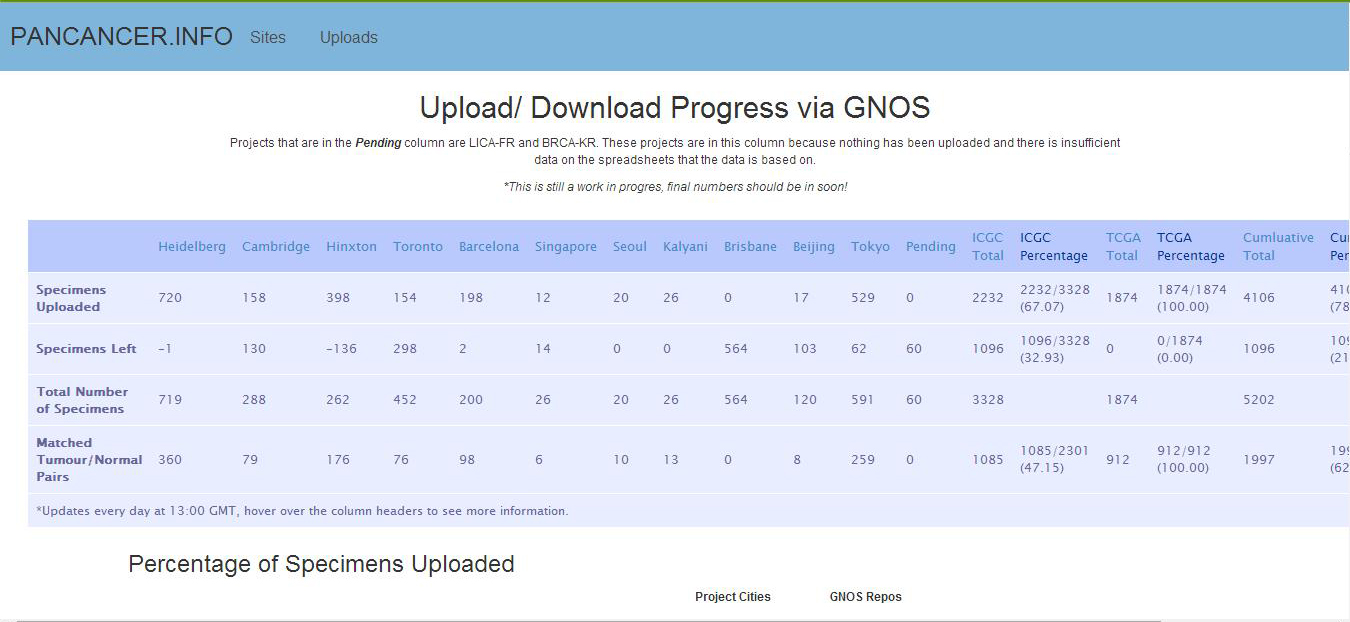
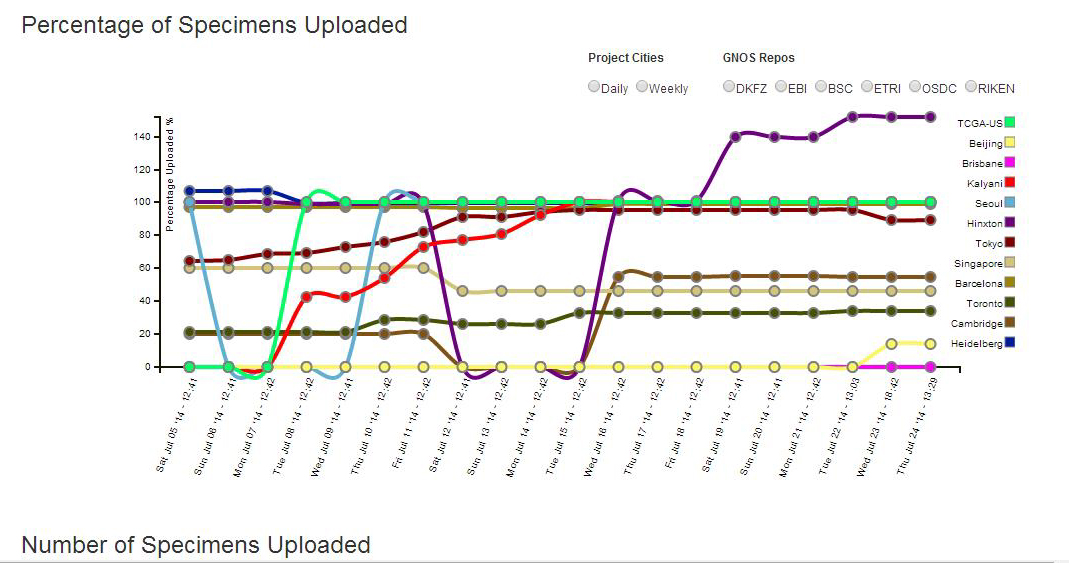
Figure 1. Contribution of India – Project in the ICGC – TCGA Pan – Cancer database as on 24 July 2014.
References & Reprints
-
India Project Team of the International Cancer Genome Consortium [Corresponding Author: MAJUMDER PP] (2013) Mutational landscape of gingivo-buccal oral squamous cell carcinoma reveals new recurrently-mutated genes and molecular subgroups. Nature Communications 4:2873 doi: 10.1038/ncomms3837. Reprint: Nature Communications 4:2873 doi: 10.1038/ncomms3837
-
Popular Version: Frontline article
